Hover over the environments below to see them in action
 BalanceBeam3D
BalanceBeam3D
 BaseMotion3D
BaseMotion3D
 ClutteredRetrieval2D
ClutteredRetrieval2D
 ClutteredStorage2D
ClutteredStorage2D
 ConstrainedCupboard3D
ConstrainedCupboard3D
 DynObstruction2D
DynObstruction2D
 DynPushPullHook2D
DynPushPullHook2D
 DynPushT2D
DynPushT2D
 DynScoopPour2D
DynScoopPour2D
 Dynamo3D
Dynamo3D
 Motion2D
Motion2D
 Obstruction2D
Obstruction2D
 Obstruction3D
Obstruction3D
 Packing3D
Packing3D
 PushPullHook2D
PushPullHook2D
 Rearrange3D
Rearrange3D
 ScoopPour3D
ScoopPour3D
 Shelf3D
Shelf3D
 SortClutteredBlocks3D
SortClutteredBlocks3D
 StickButton2D
StickButton2D
 SweepIntoDrawer3D
SweepIntoDrawer3D
 SweepSimple3D
SweepSimple3D
 Table3D
Table3D
 Tossing3D
Tossing3D
 Transport3D
Transport3D
About KinDER
A physical reasoning benchmark for robot learning and planning.
Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 8 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics.
What Makes KinDER Challenging?
For Reinforcement Learning
Environments have long horizons and sparse rewards. Users are welcome to engineer dense rewards, but doing so may be nontrivial. Environments also have very diverse task distributions, so learned policies must generalize.
For Imitation Learning
Physical reasoning requires understanding physical constraints (e.g., spatial relationships, kinematics, dynamics). Imitating surface-level patterns in demonstrations is not enough to generalize to broad task distributions.
For Vision-Language Models
The physical reasoning required in KinDER is not easy to represent in natural language. Spatial reasonining, a subset of physical reasoning, is a known challenge for vision-language models.
For Hierarchical Approaches
Approaches that first decide "what to do" and then decide "how to do it" -- whether in hierarchical RL, planning, or with multi-level foundation models -- will run into difficulties when there are couplings between these high-level and low-level decisions.
For Task and Motion Planning
KinDER does not provide any models for TAMP. Users are welcome to engineer their own, but doing so may be nontrivial. Some environments contain many objects, which may make planning slow.
For Human Engineers
KinDER features diverse task distributions and long time horizons, making it challenging for engineers to hand-design even very environment-specific solutions. A single task may be straightforward, but designing generalized solutions is nontrivial.
Installation and Usage
Installation
pip install kindergarden # Core dependencies only
pip install kindergarden[all] # All environment dependencies
# Or install specific environment categories
pip install kindergarden[kinematic2d]
pip install kindergarden[dynamic2d]
pip install kindergarden[kinematic3d]
pip install kindergarden[dynamic3d]
For development or installing from source, see the GitHub repository.
Basic Usage (Gym API)
import kinder
kinder.register_all_environments()
env = kinder.make("kinder/Obstruction2D-o3-v0") # 3 obstructions
obs, info = env.reset() # procedural generation
action = env.action_space.sample()
next_obs, reward, terminated, truncated, info = env.step(action)
img = env.render()Object-Centric States
All environments in KinDER use object-centric states:
from kinder.envs.geom2d.obstruction2d import ObjectCentricObstruction2DEnv
env = ObjectCentricObstruction2DEnv(num_obstructions=3)
obs, _ = env.reset(seed=123)
print(obs.pretty_str())Here, obs is an ObjectCentricState, and the printout is:
############################################################### STATE ###############################################################
type: crv_robot x y theta base_radius arm_joint arm_length vacuum gripper_height gripper_width
----------------- -------- -------- ------- ------------- ----------- ------------ -------- ---------------- ---------------
robot 0.885039 0.803795 -1.5708 0.1 0.1 0.2 0 0.07 0.01
type: rectangle x y theta static color_r color_g color_b z_order width height
----------------- -------- -------- ------- -------- --------- --------- --------- --------- --------- ---------
obstruction0 0.422462 0.100001 0 0 0.75 0.1 0.1 100 0.132224 0.0766399
obstruction1 0.804663 0.100001 0 0 0.75 0.1 0.1 100 0.0805652 0.0955062
obstruction2 0.559246 0.100001 0 0 0.75 0.1 0.1 100 0.12608 0.180172
type: target_block x y theta static color_r color_g color_b z_order width height
-------------------- ------- -------- ------- -------- --------- --------- --------- --------- -------- --------
target_block 1.20082 0.100001 0 0 0.501961 0 0.501961 100 0.138302 0.155183
type: target_surface x y theta static color_r color_g color_b z_order width height
---------------------- -------- --- ------- -------- --------- --------- --------- --------- -------- --------
target_surface 0.499675 0 0 1 0.501961 0 0.501961 101 0.180286 0.1
#####################################################################################################################################For compatibility with baselines, observations are provided as vectors. Convert between vectors and object-centric states:
import kinder
kinder.register_all_environments()
env = kinder.make("kinder/Obstruction2D-o3-v0")
vec_obs, _ = env.reset(seed=123)
object_centric_obs = env.observation_space.devectorize(vec_obs)
recovered_vec_obs = env.observation_space.vectorize(object_centric_obs)Baselines
We provide implementations of several baselines in the kinder-baselines repository. Installation and usage instructions are available there.
Bilevel Planning
TAMP-style bilevel planning
Domain-Specific Policies
Hand-engineered policies with domain-specific models
Diffusion Policies
Learning from demonstrations
Reinforcement Learning
RL with sparse and shaped rewards
VLA Policies
Finetuning pi-0.5 with demonstrations
LLM & VLM Planning
Large language and vision-language model based planning
Tutorials
Step-by-step tutorials for getting started with KinDER.
KinDERGarden: Environments
KinDER environments are organized into four categories.
Kinematic 2D
- ClutteredRetrieval2D 3 variants
- ClutteredStorage2D 4 variants
- Motion2D 6 variants
- Obstruction2D 5 variants
- PushPullHook2D 1 variant
- StickButton2D 5 variants
Kinematic 3D
- BaseMotion3D 1 variant
- Obstruction3D 5 variants
- Packing3D 3 variants
- Table3D 3 variants
- Transport3D 2 variants
Dynamic 2D
- DynObstruction2D 4 variants
- DynPushPullHook2D 3 variants
- DynPushT2D 1 variant
- DynScoopPour2D 4 variants
Dynamic 3D
- BalanceBeam3D 1 variant
- ConstrainedCupboard3D 3 variants
- Dynamo3D 2 variants
- Rearrange3D 20 variants
- ScoopPour3D 1 variant
- Shelf3D 8 variants
- SortClutteredBlocks3D 6 variants
- SweepIntoDrawer3D 1 variant
- SweepSimple3D 6 variants
- Tossing3D 2 variants
KinderBench: Benchmark and Results
See the plot below for a summary of our main empirical results. See paper for details and additional results with additional metrics.
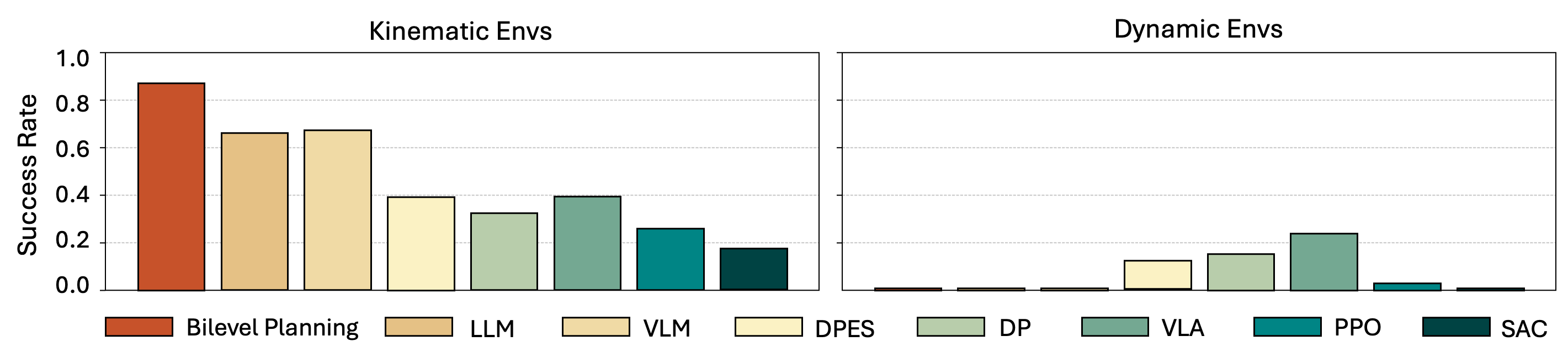
Success rates: mean ± std across 5 seeds and 50 episodes per seed.
Real Robot Validation
Real robot versions of KinDER tasks with real-to-sim-to-real planning.